Tokenizing is pretty okay
I'm making progress on the lexer. The flowchart helped a whole lot. So far, I've managed to loop through a program and separate it into tokens. I added some print statements to the code so it's easy to see what the program is doing:
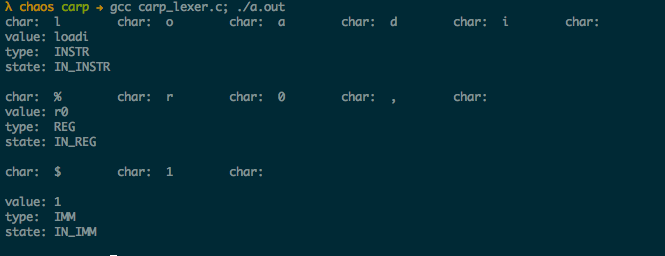
Several things are happening. First, I compile the lexer program:
gcc carp_lexer.c
I did not specify an output file for the "binary", or machine-readable program, and the default is "a.out" — so it writes to that file. The compiler then marks that file as "executable" so I can run it with:
./a.out
...and I do just that. The lexer goes through each individual character in the program, which is currently only:
loadi %r0, $1
Since the "l" is the first character in the program, it says "okay, this must be an instruction" and sets the state to "IN_INSTR". When it hits the space between "loadi" and "%r0", it sets aside some space to hold "loadi", then clears the buffer, and continues.
Since a "%" is the first character after the space, the lexer things "oh, okay — this must be a register name" and sets the state to "IN_REG". It continues until the next space, and then sets aside more space to hold "r0", the register name.
The lexer sees the comma as a separator, ignores it, then hits the "$". It says, "okay, this is an immediate value" and sets the state accordingly. When it sees the newline (or end of string null-byte, '\0') it sets aside space, and then continues.
This program ALMOST works. The bit that isn't working is invisible... it's supposed to print something but doesn't. What I would like to happen is for the lexer to print out a series of tokens and their associated types. The only problem is that the bit of memory that points to the location of the token list points to the END of the token list.
I'm trying to figure out a way to keep a pointer to the start of the list, but so far that trivial problem has proved not so trivial.
Until next time.